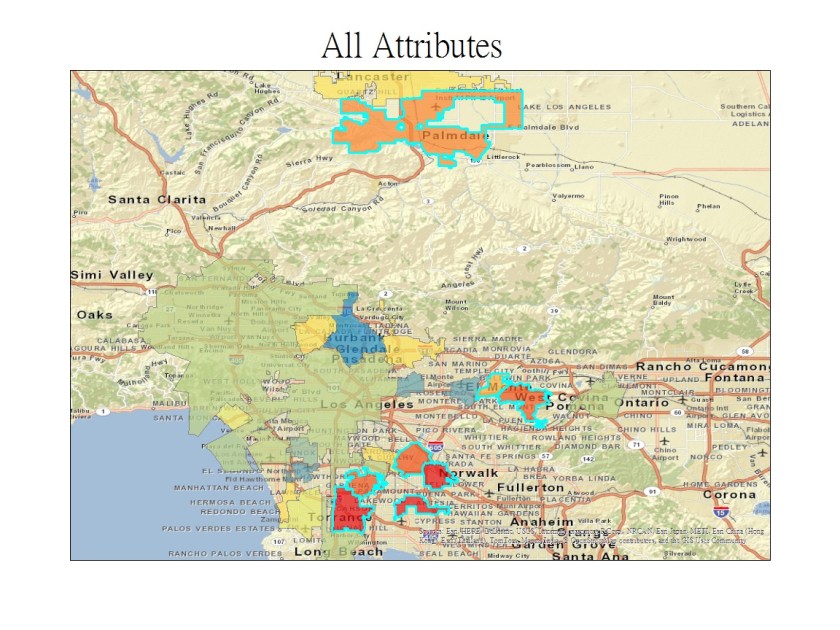
Analyzing Density Bonus Developments in the City of Los Angeles
On February 22, 2016, I started the GIS Specialization Course with UC Davis through Coursera. For those of you who have paid attention, I have started the final course of the specialization: Geospatial Analysis Project. As with other Coursera specializations, this is a Capstone project that is the culmination of the previous courses. For this project, I have to propose, design, analyze, and present a geospatial analysis project from start to finish. This week requires the creation of my project proposal, which is as follows (if any of you have suggestions on data sources and/or analysis, please feel free to comment): What is Density Bonus? Density Bonus is a program through which a developer can apply for a project with a unit density greater than that allowed by the current land use zoning, as calculated from unit floor area and floor area ratio (FAR). In exchange for the higher density, the developer must set aside a certain number of units to be affordable: this is by restricting the rent levels or sale prices to targeted income levels …